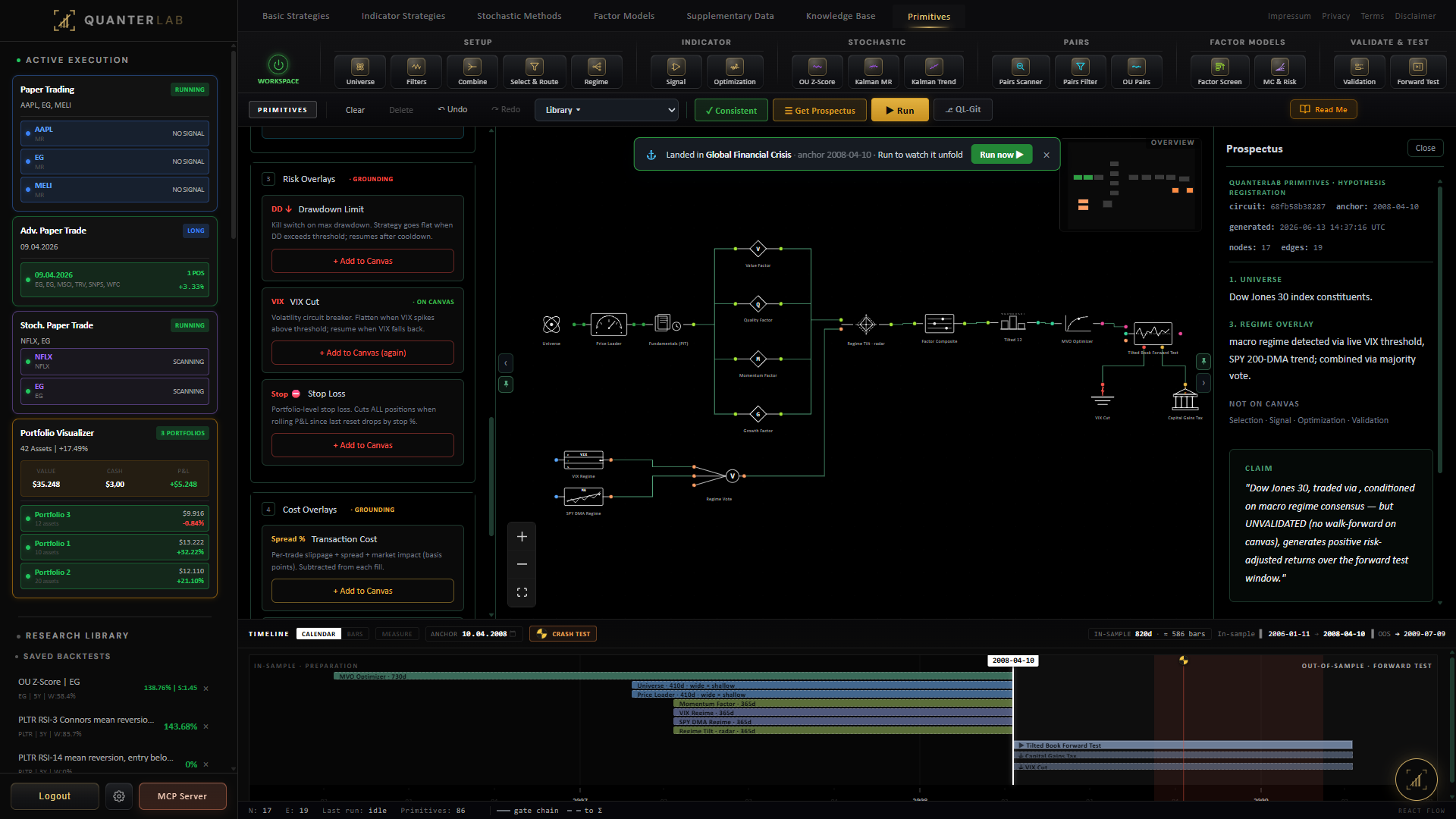
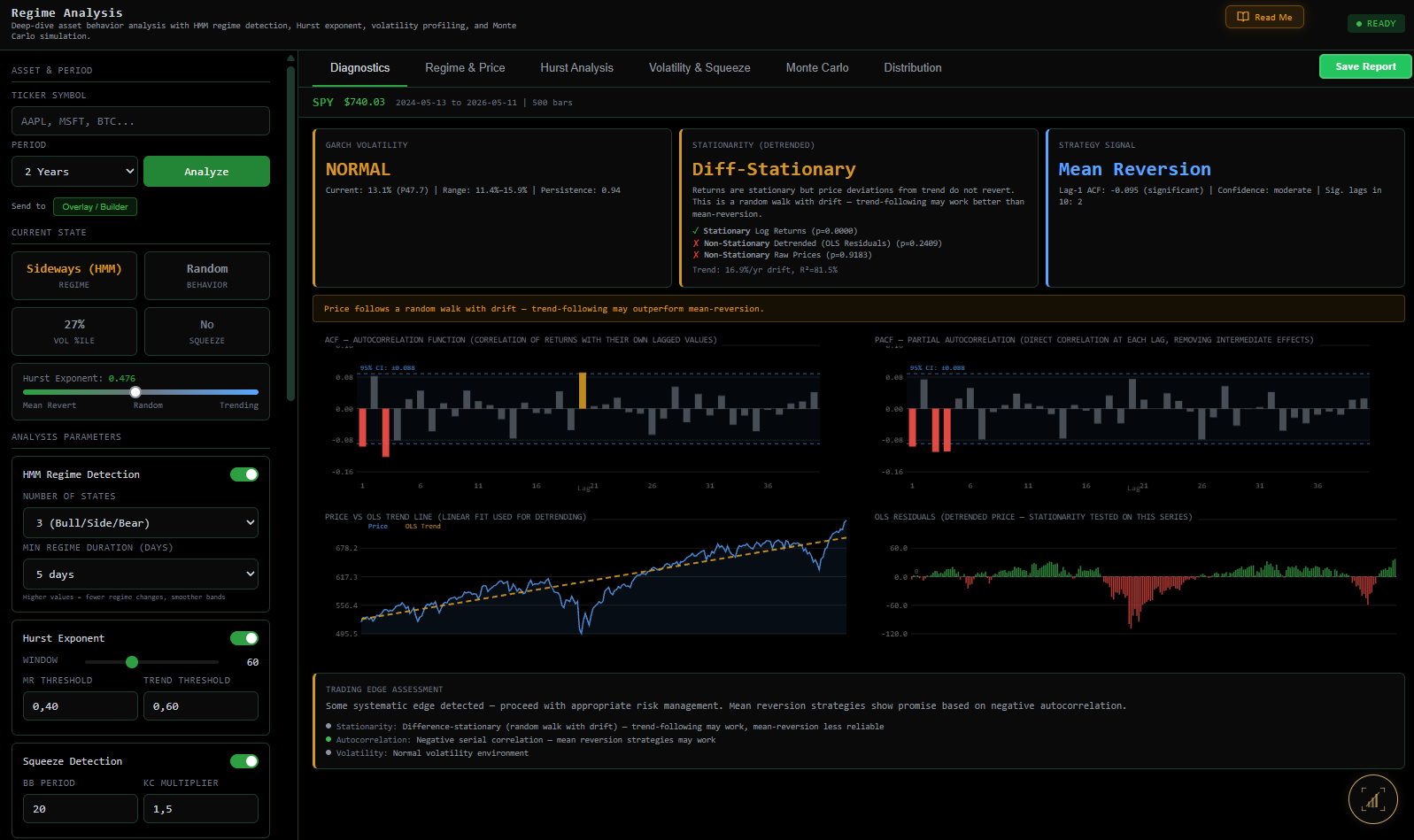
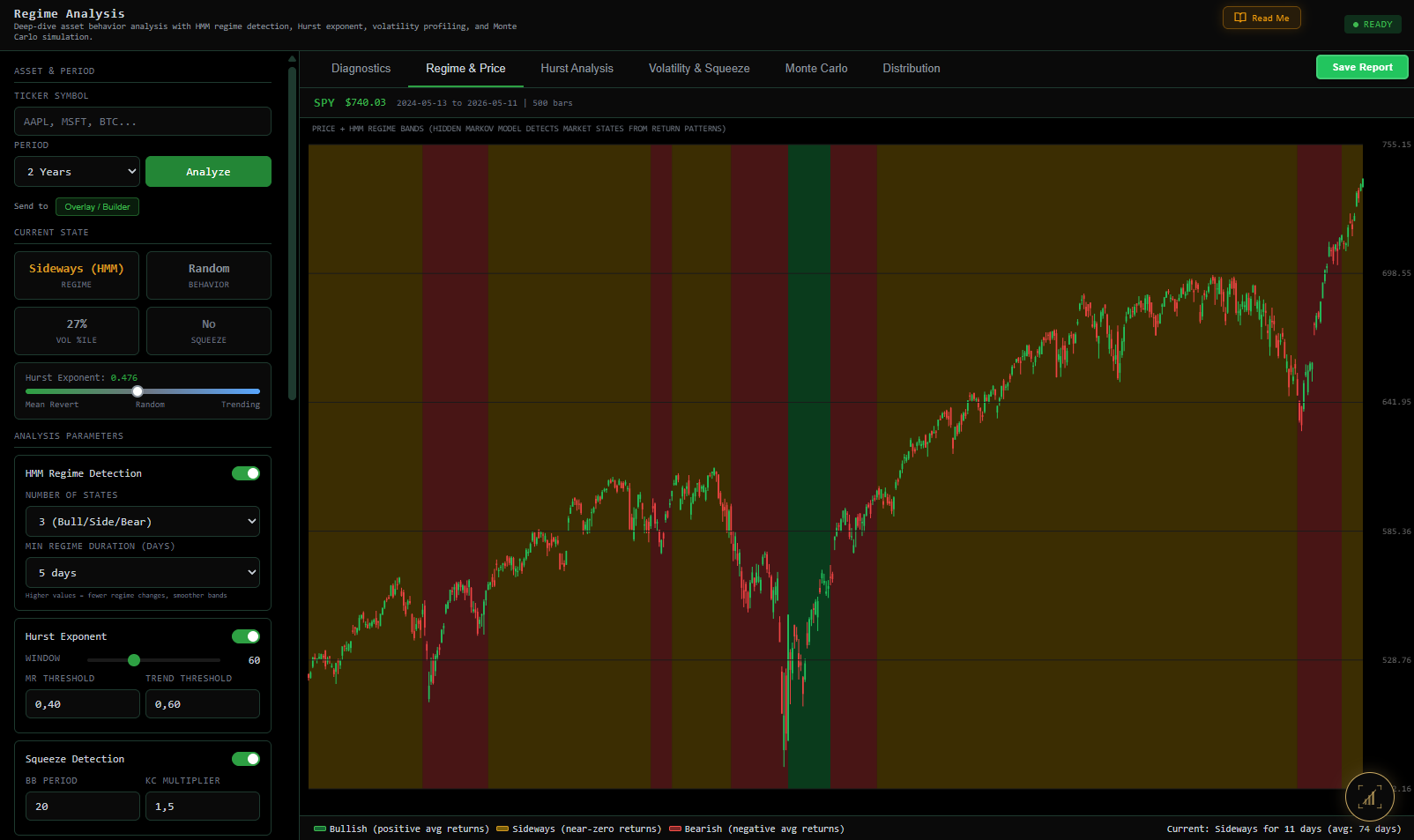
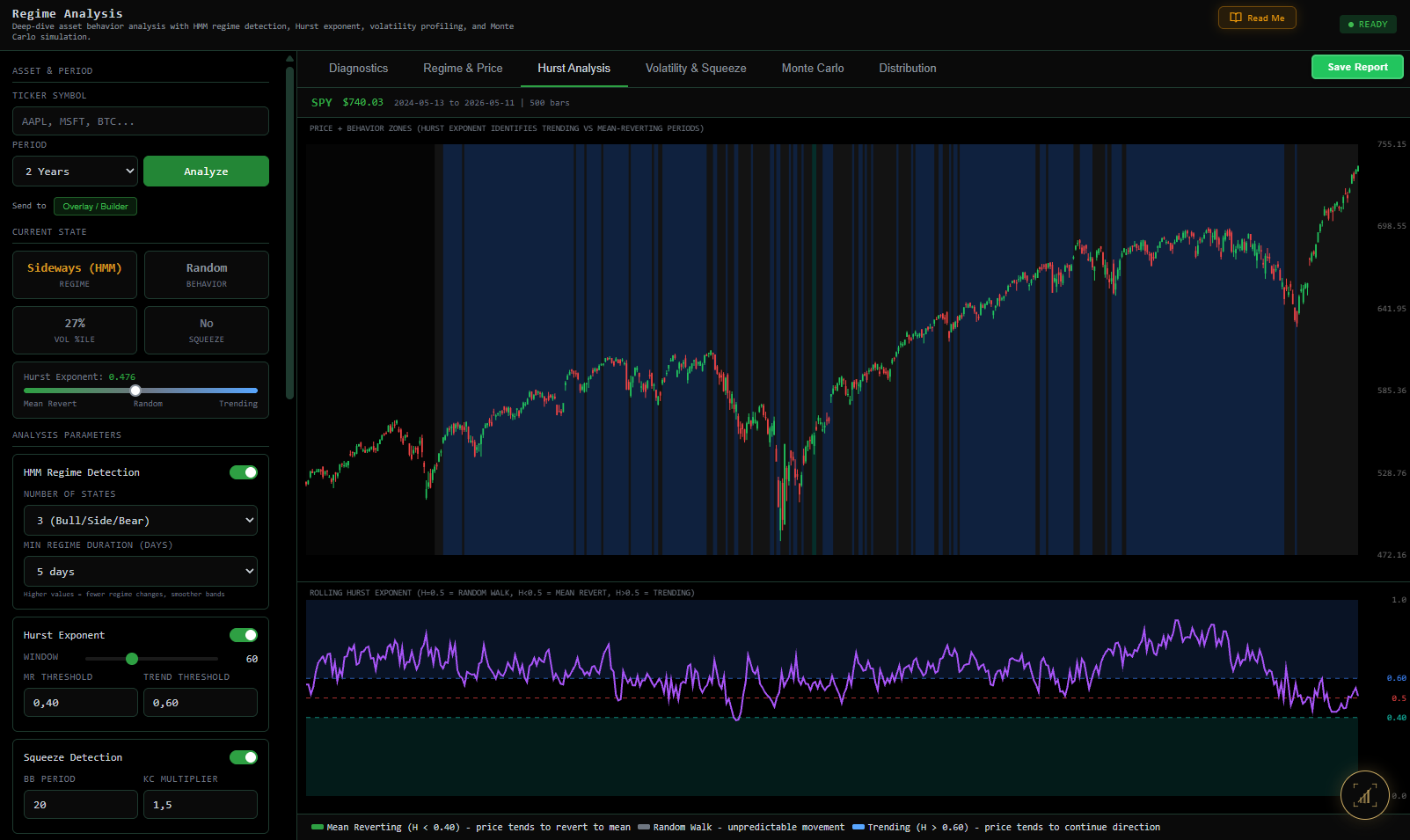
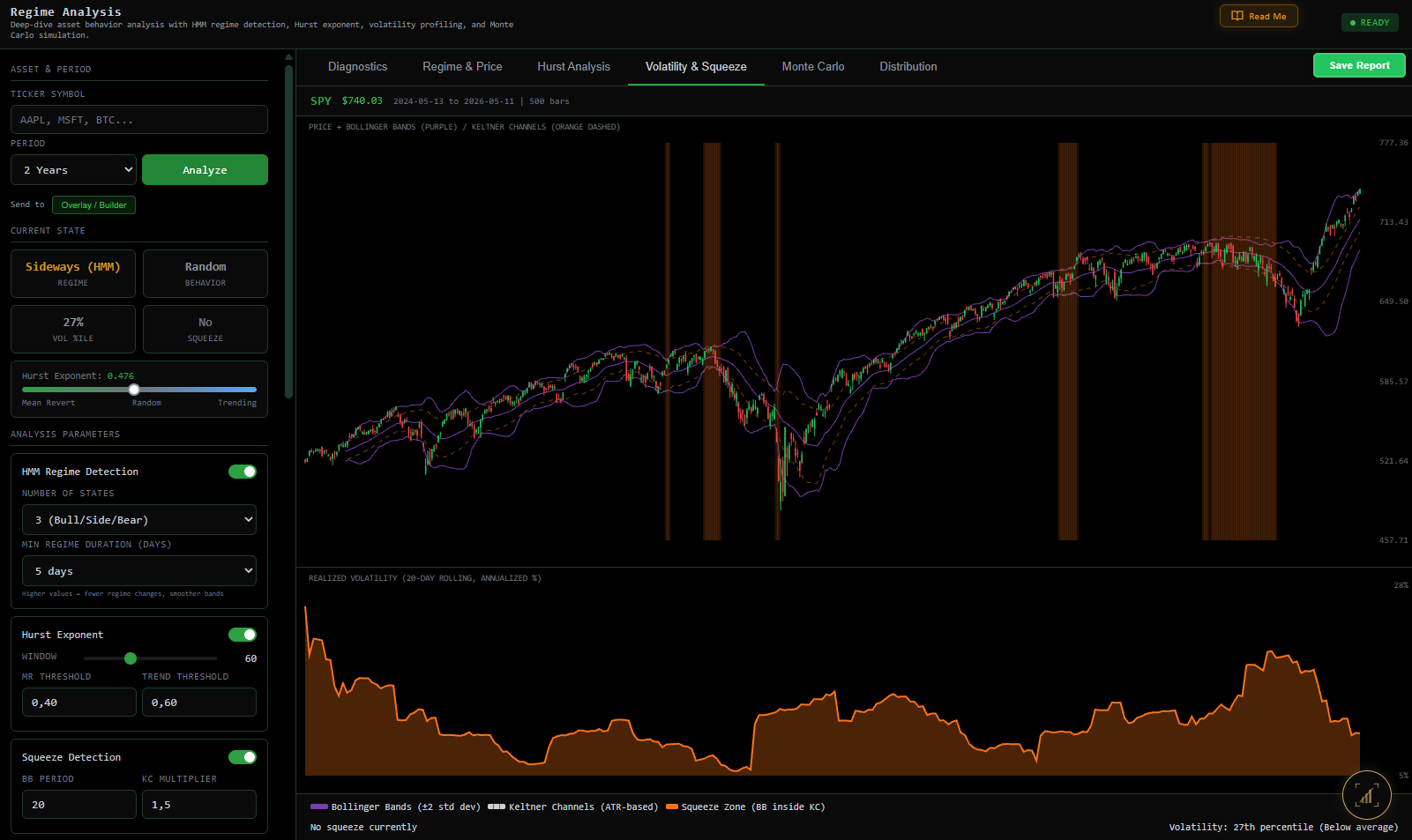
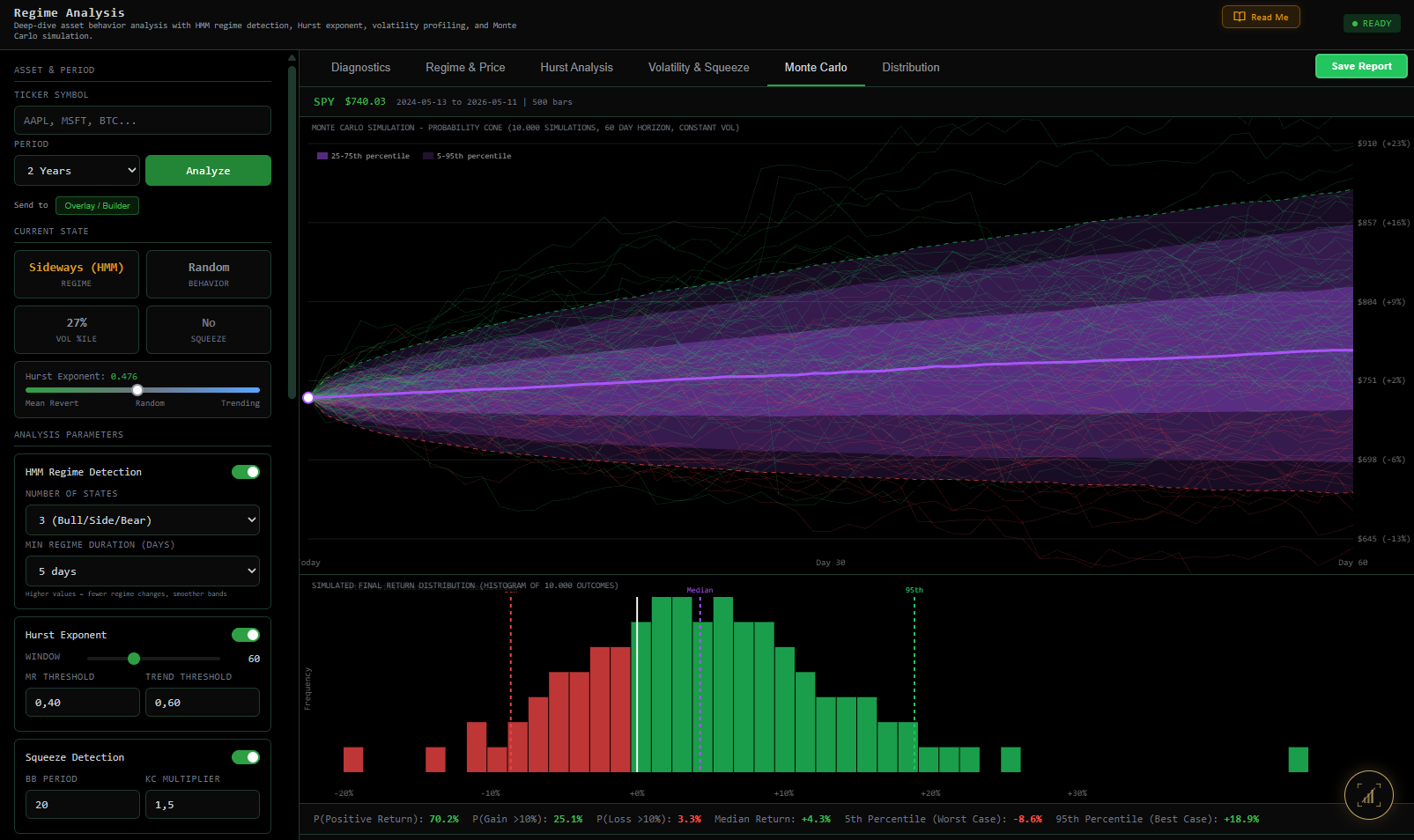
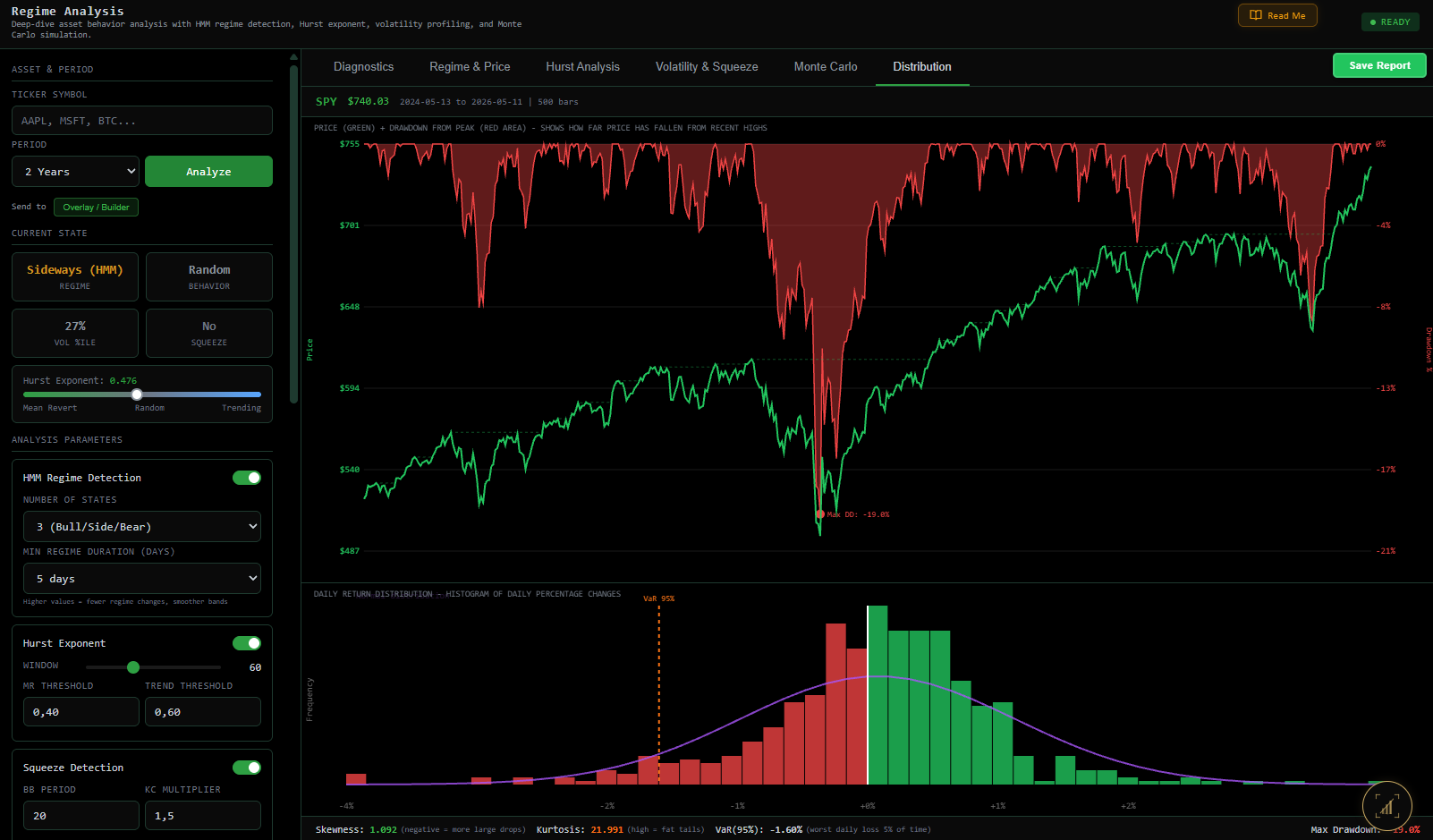
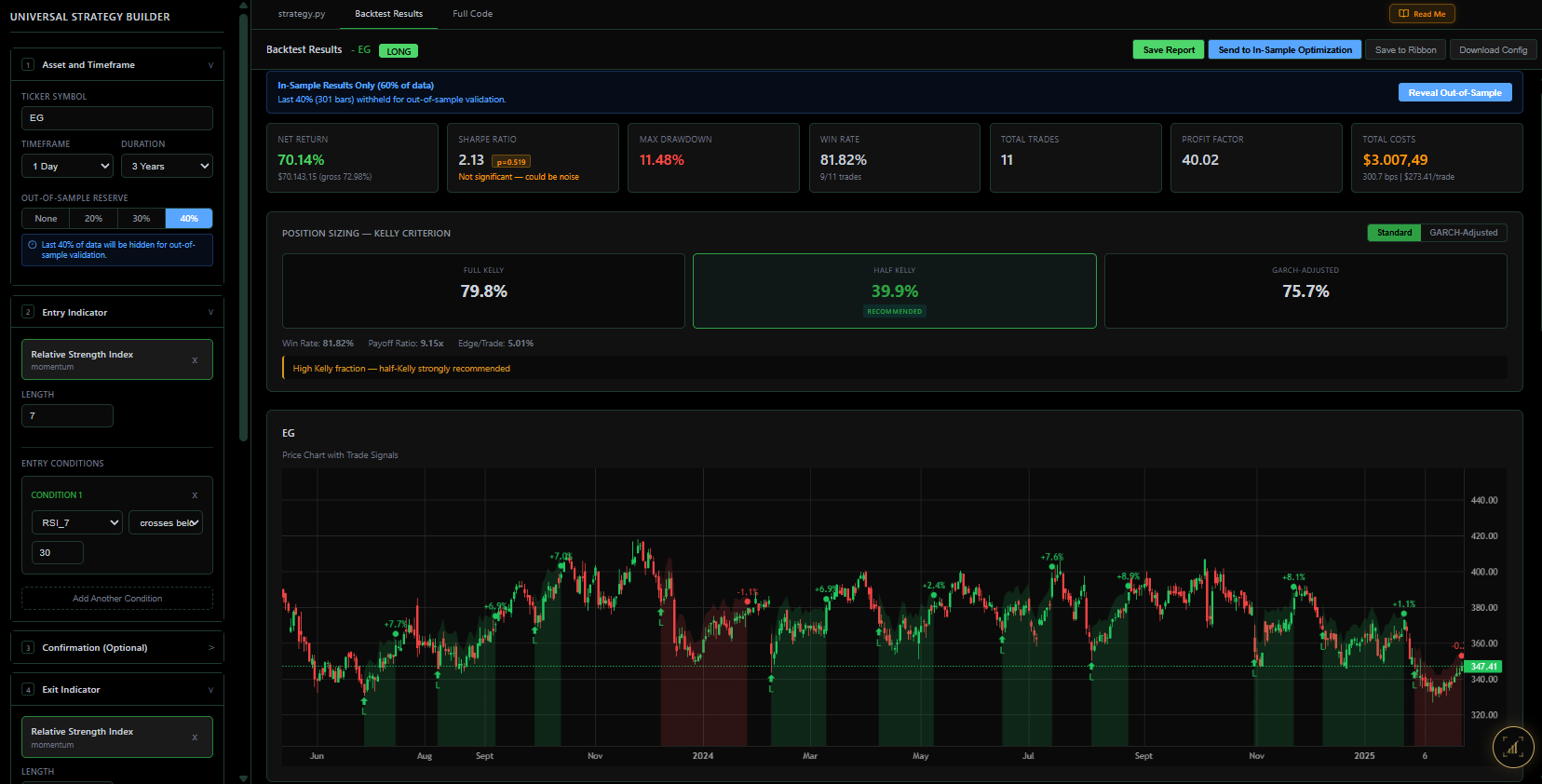
Quantin
Mathematician lens
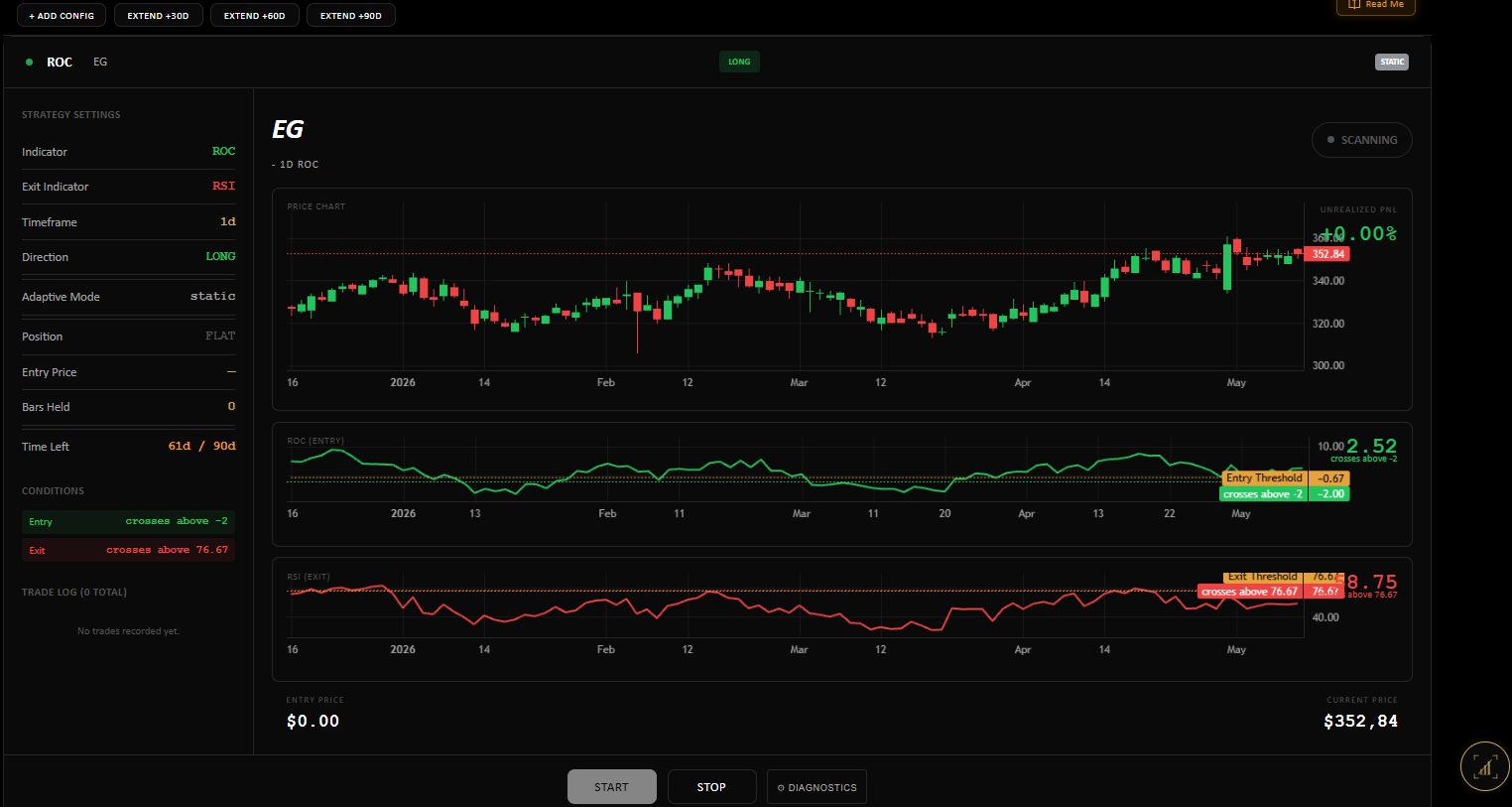
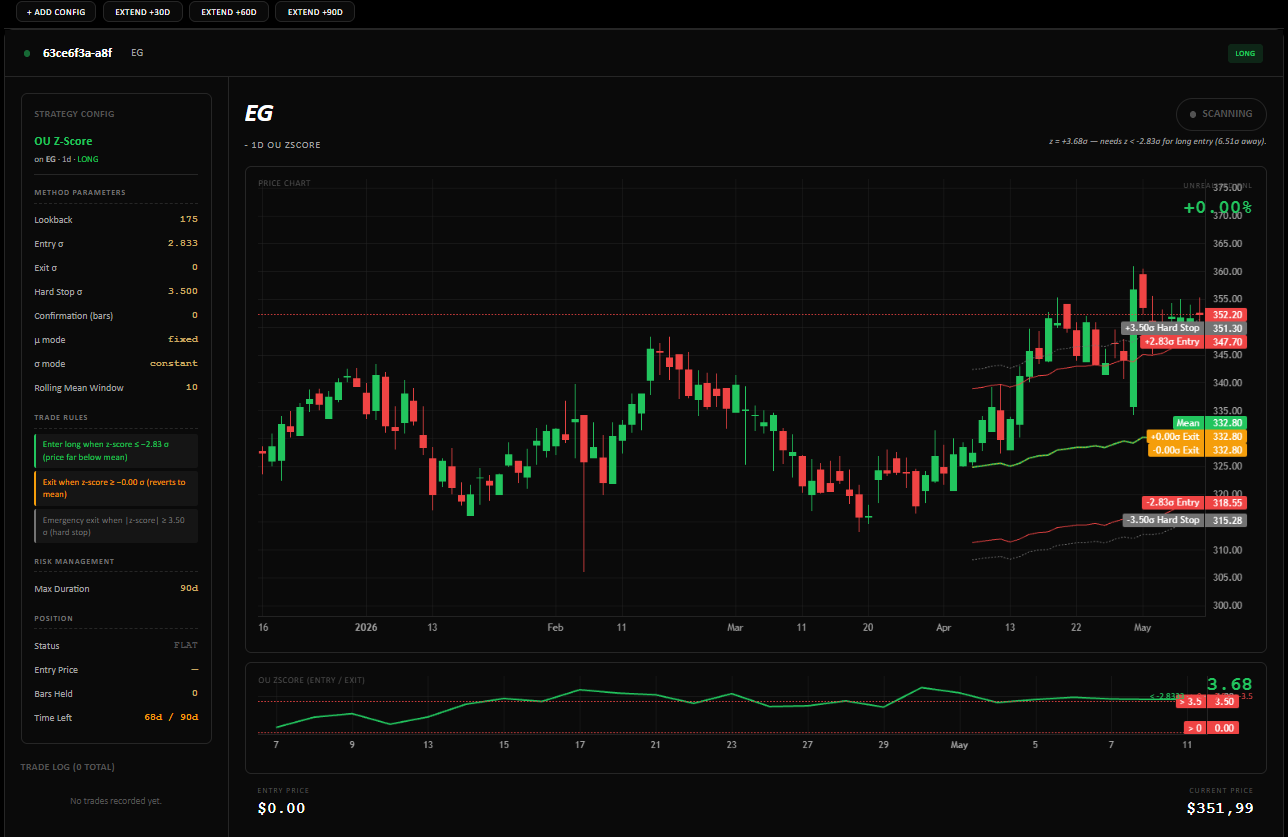
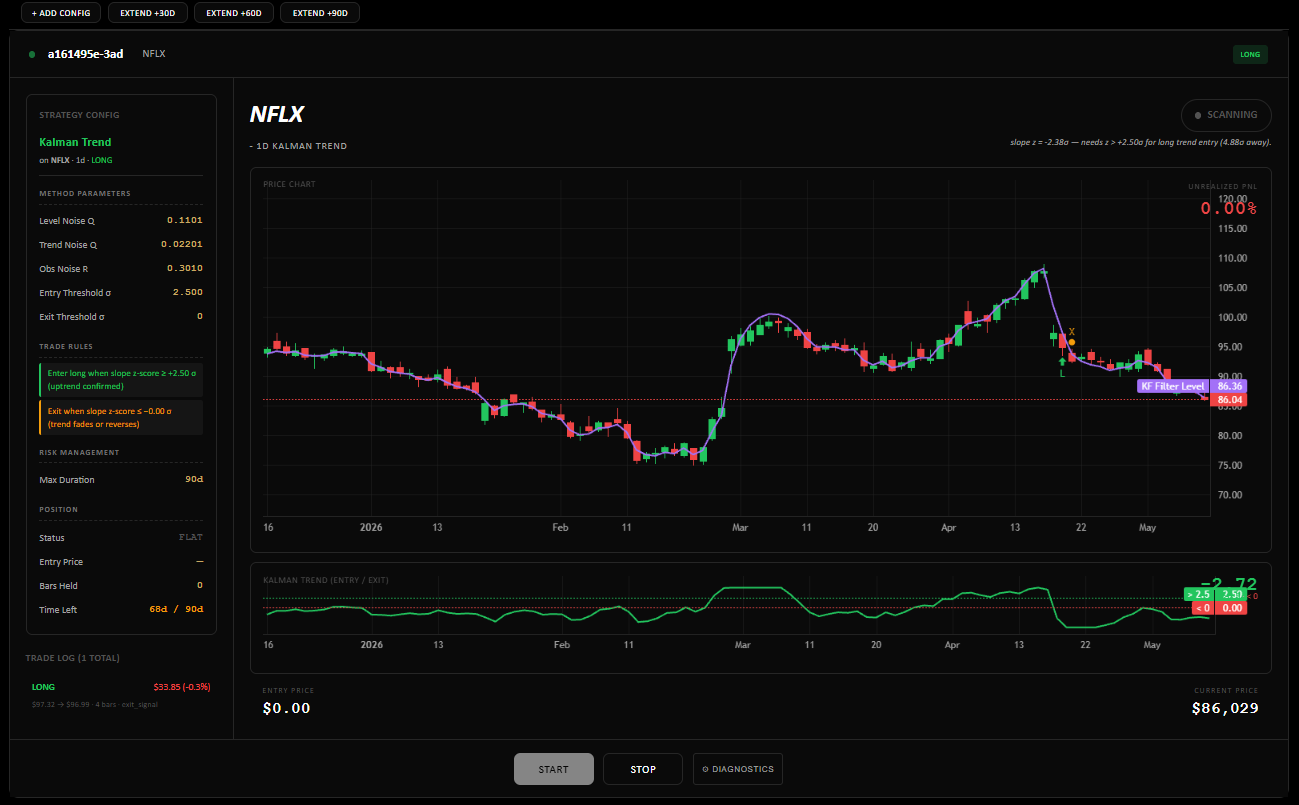
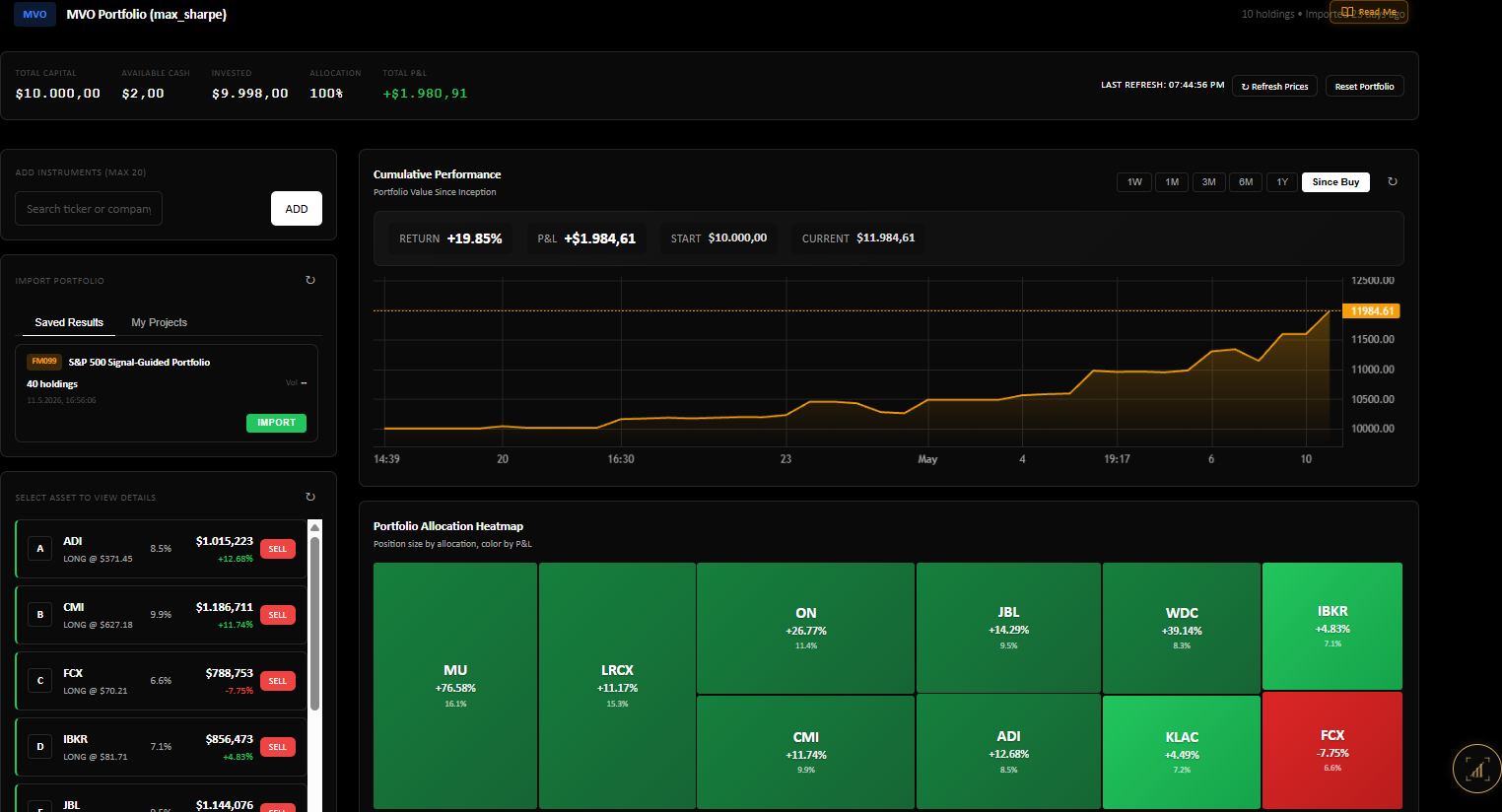
Ornstein-Uhlenbeck — mean reversion as a stochastic process.
Start with the continuous-time SDE. The process is pulled back toward its long-run mean \(\mu\) at speed \(\theta\), perturbed by Brownian noise of size \(\sigma\):
\[ dX_t = \theta\,(\mu - X_t)\,dt + \sigma\,dW_t \]
Three parameters, three meanings. \(\theta\) is the speed of reversion — large \(\theta\) snaps back fast. \(\mu\) is the level it reverts to. \(\sigma\) is the noise scale — the width of the band around \(\mu\) the process explores.
From \(\theta\) you get the most actionable quantity, the half-life — the expected time for a deviation from the mean to shrink by half:
\[ t_{1/2} = \frac{\ln 2}{\theta} \]
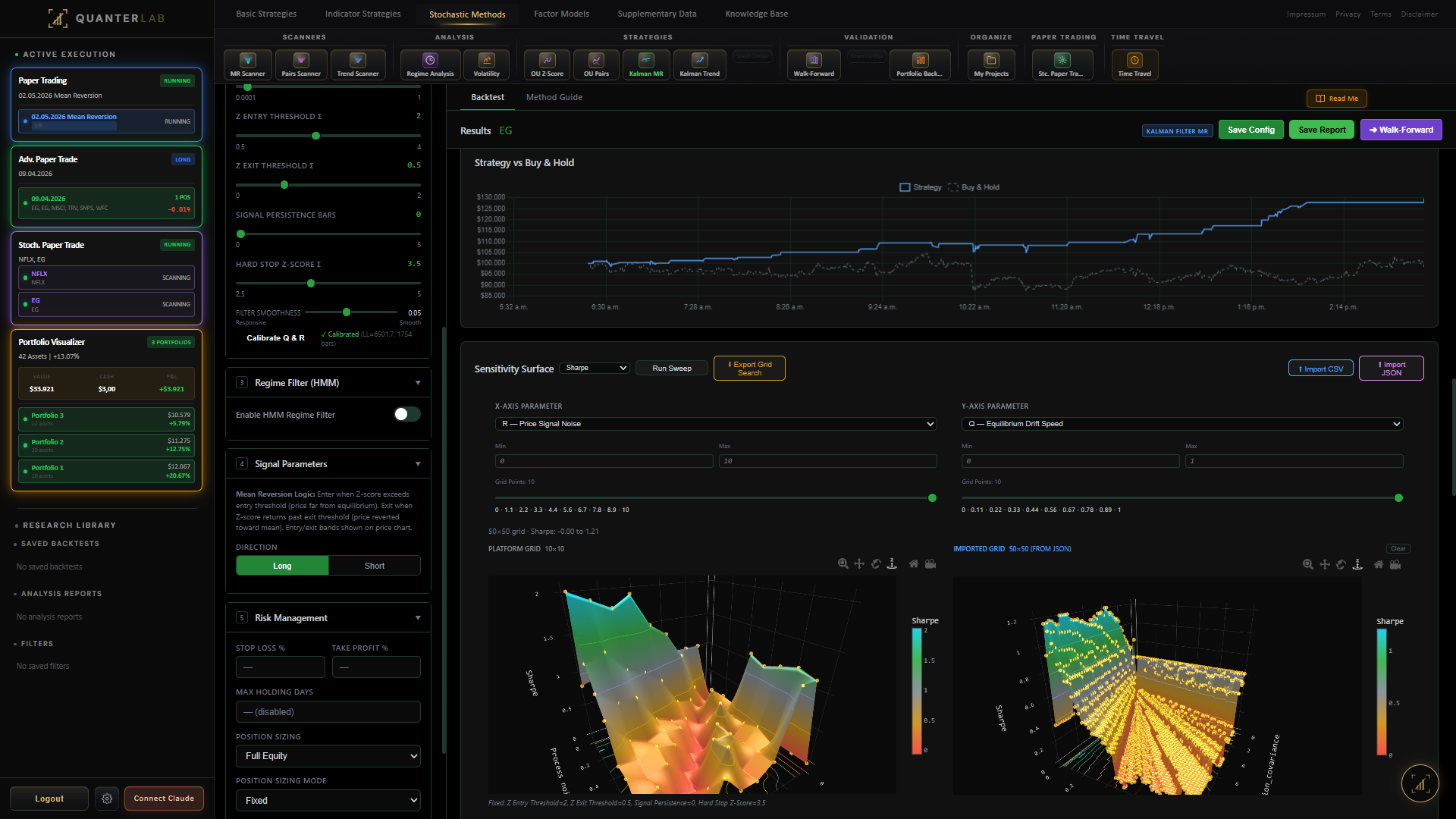
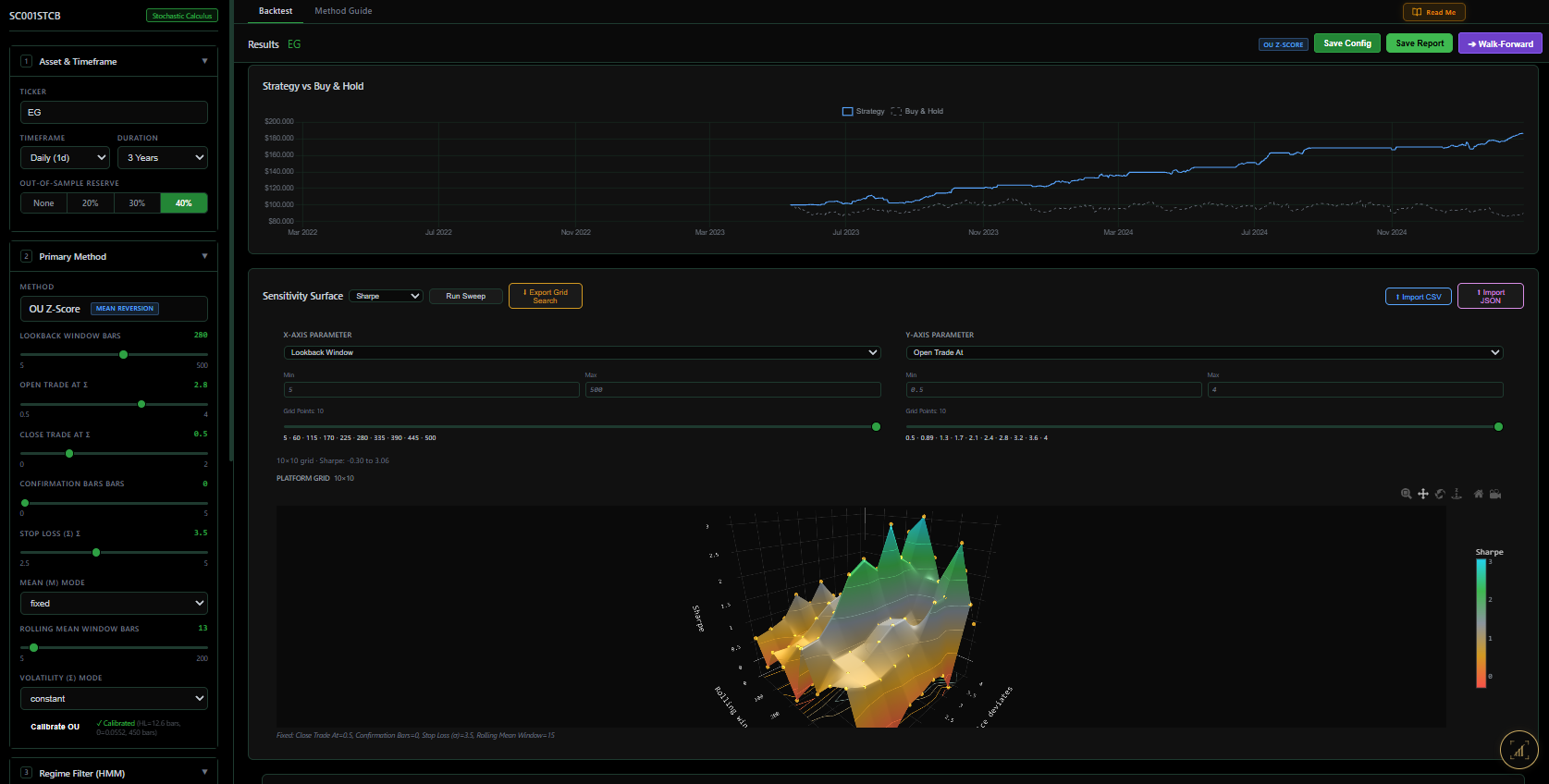
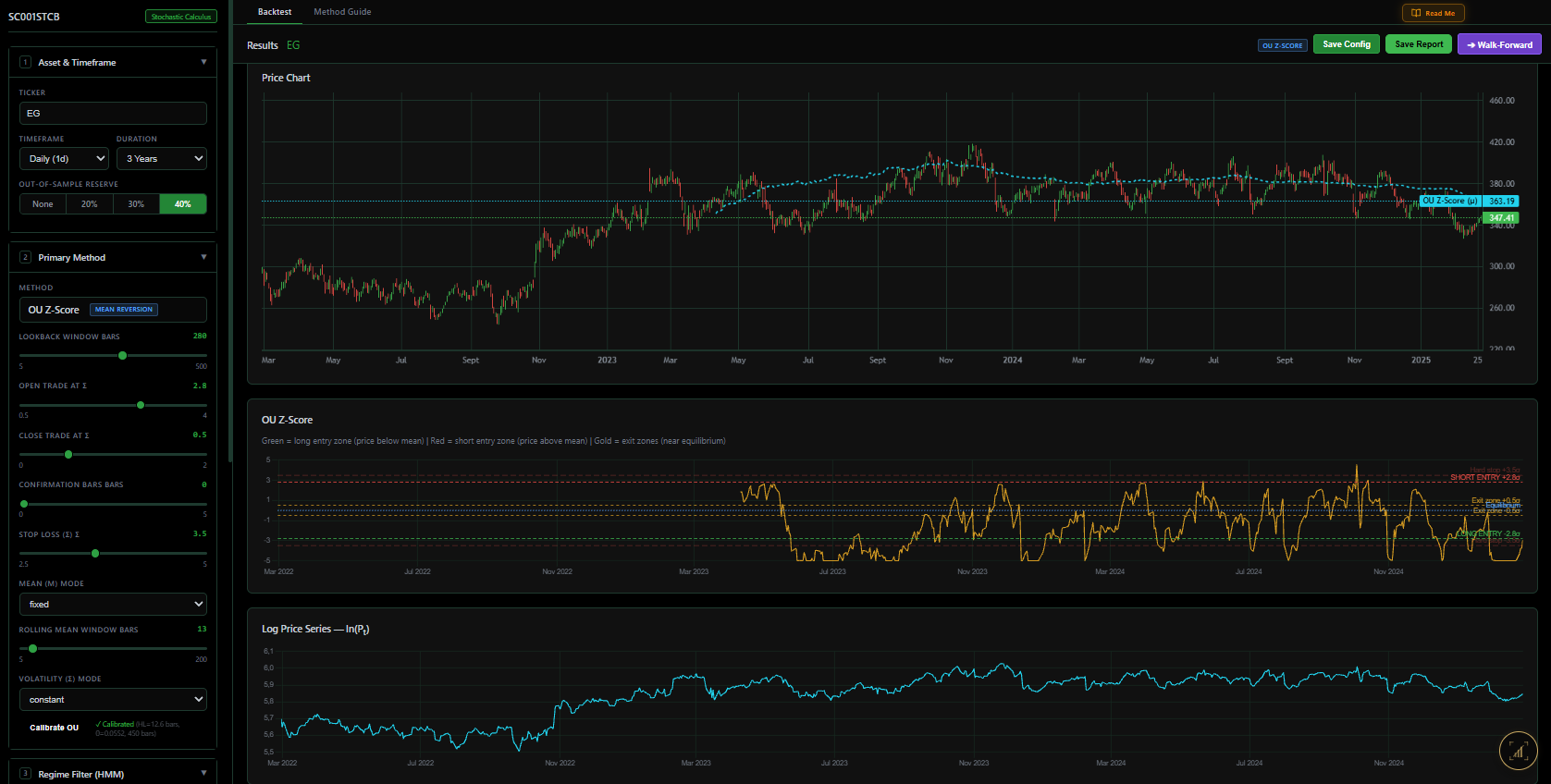
And the trading signal — the z-score at each bar — is just the standardised deviation from the fitted mean:
\[ z_t = \frac{X_t - \mu}{\sigma / \sqrt{2\theta}} \]
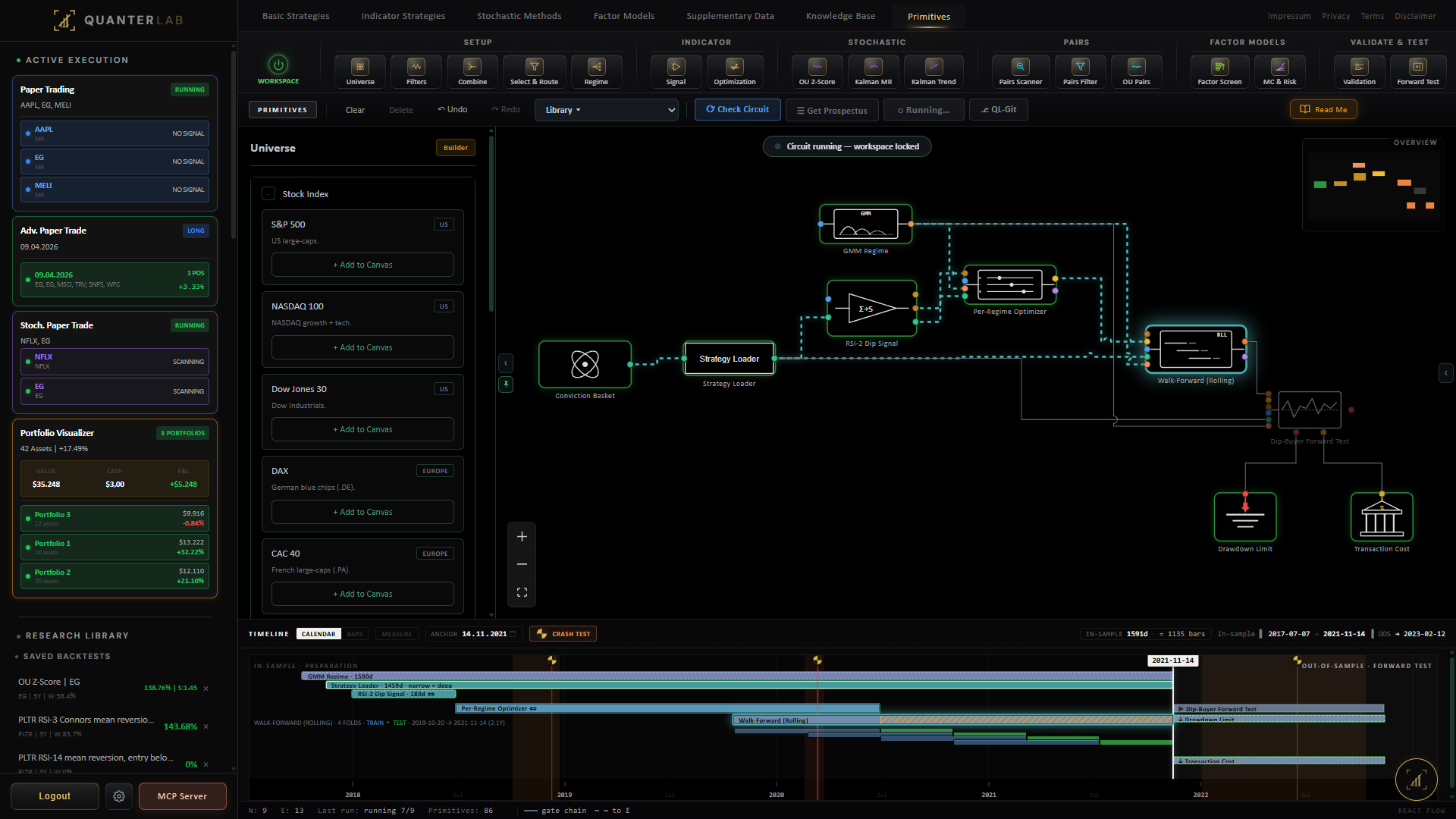
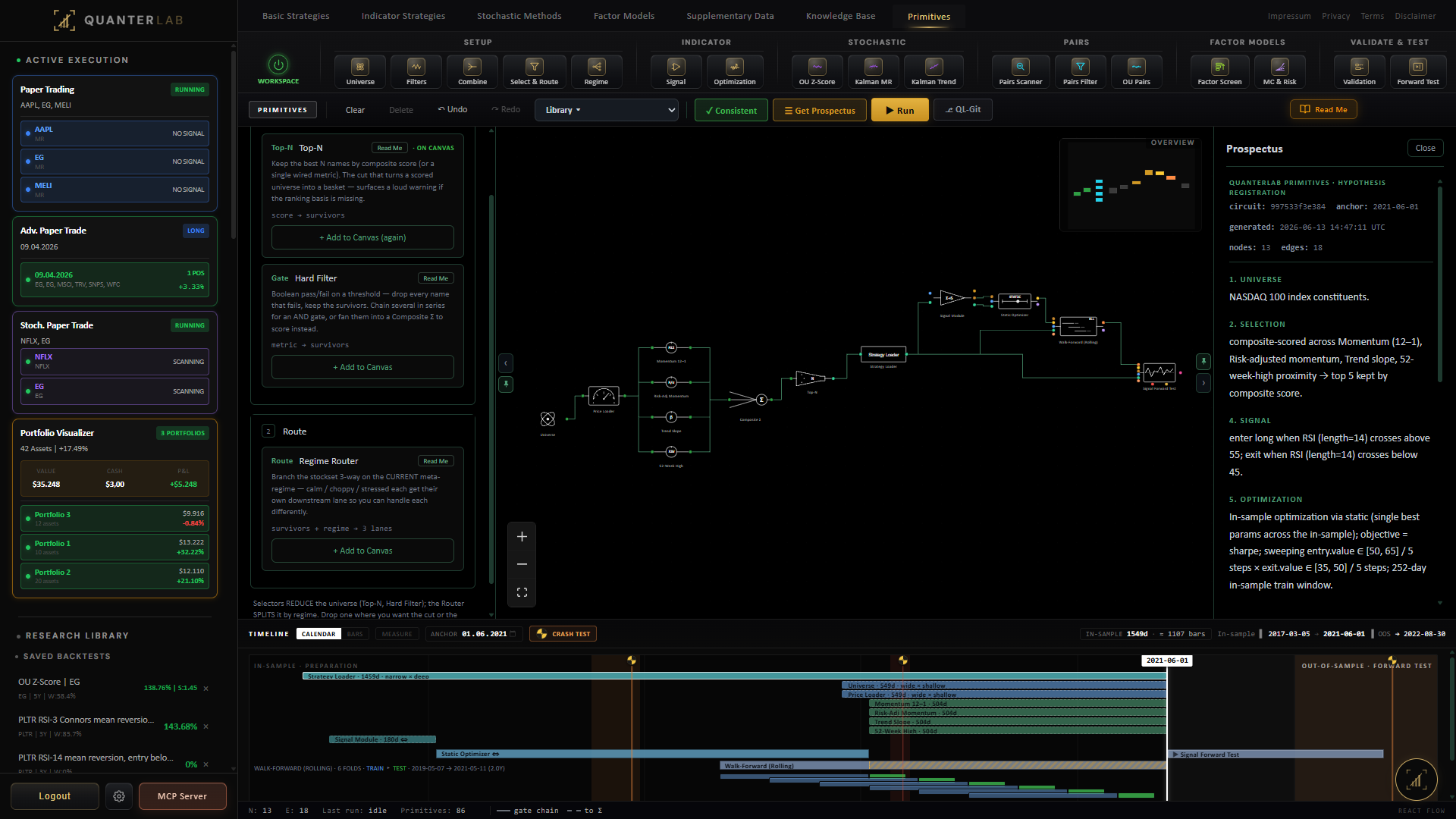
The Stochastic Builder fits \((\theta, \mu, \sigma)\) by maximum likelihood on the discretised AR(1) form. Want me to walk through the AR(1) derivation, or show how the half-life maps to the platform's signal-window control?